




Natural Language Processing (NLP) has come a long way in the past few decades. With the goal of enabling more efficient communication between humans and machines, it has evolved from rule-based systems to more advanced methods like deep learning. Most prominently, Large Language models (LLMs) have emerged as one of the most fascinating technologies since the dawn of the Internet. And for software makers looking to leverage LLMs, Retrieval-Augmented Generation (RAG) is rapidly becoming the preferred approach.
Discover the power of retrieval-augmented generation and how it pushes the boundaries of LLMs and generative AI models, further bridging the gap between human communication and artificial intelligence.
Limitations of LLMs
LLMs are neural network models that are pre-trained on massive amounts of data to understand, generate, and predict new content, breaking down language barriers to performing human tasks. LLMs such as GPT-3 (Generative Pre-trained Transformer 3) are used to train generative AI models like ChatGPT.
But as much as LLMs can produce intelligent content, they can only be as intelligent as the data they were trained on. For an LLM to understand and be able to generate content related to specific data, it must either undergo pre-training using that data or have that data supplied through a “context window.” Pre-training involves resource-intensive and time-consuming processes like data collection, pre-processing, and running numerous iterations over the dataset.
An LLM’s knowledge stops once training is complete. For example, ChatGPT 4’s knowledge stops in April 2023. If you ask it about any recent event, it will either refuse to respond, respond with potentially outdated information, or in the worst case, invent a plausible-sounding response. Although LLMs have a context window by which new information can be passed in, all LLM context windows are relatively limited in size and cannot accommodate most reasonably-sized datasets.
When an LLM lacks information to respond to a query, it may respond by fabricating information, a result described as a “hallucination.” In the below example, ChatGPT responds with the “Hugging Face Transformers Library” when asked what framework can be used for LLM development. Its response is incorrect as it refers to a library and not a framework. A more fitting response would talk about current frameworks such as LangChain.

Another problem with LLMs is that they lack inherently reliable measures for upholding data tenancy boundaries and access controls, potentially leading to scenarios where data becomes visible to users who should not have access.
What is Retrieval-Augmented Generation?
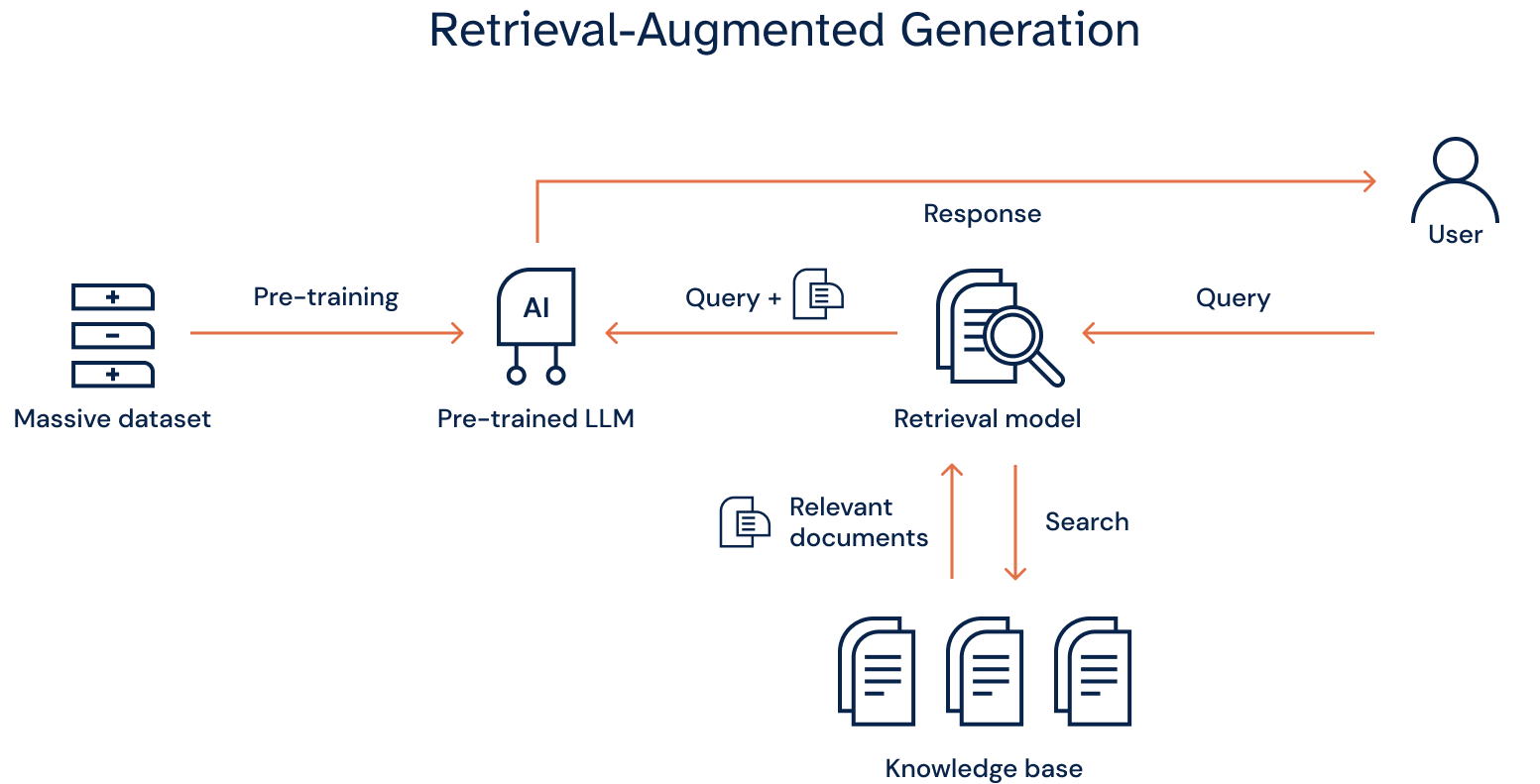
RAG is an innovative approach that introduces a retrieval method prior to the generation stage of an LLM. At its core, RAG aims to improve an LLM’s ability to generate more intelligent and accurate responses by leveraging retrieval-based methods and generative model skills for producing natural language output. It also utilizes semantic search capabilities to recognize the context between words and provide results that are relevant to the original query.
RAG addresses some of the limitations of LLMs, such as generating factually incorrect information or being sensitive to input phrasing variations. It also enables the incorporation of external knowledge which can be beneficial for tasks such as answering queries and content creation where access to broad knowledge bases can improve the LLM’s output.
Catch the full interview here.
How can RAG improve LLMs?
Real-time data queries
By integrating RAG with LLMs, RAG extends the capability of language models to harness real-world information and accurate, timely data outside of their training sets without the need for retraining. This then allows the LLM to provide more high-quality responses.
RAG fetches real-time data with the LLM assisting in generating data queries based on natural language queries. The generator model can then receive and refine the narrowed-down results through the LLM’s context windows, ultimately returning a natural language response.
Flexibility in data restrictions
With RAG, restrictions on data queries can be seamlessly integrated into the retrieval process to comply with data tenancy, privacy, and other regulatory requirements. Organizations can enforce rules and guidelines governing data access, usage, and sharing to preserve privacy and confidentiality.
Through customized query filtering, organizations can ensure that access is restricted only to data that complies with specific privacy regulations or is owned by particular entities in accordance with legal agreements. This enables organizations to leverage the power of large datasets while maintaining compliance with regulatory requirements and data governance policies.
The Components of RAG
RAG models consist of two main components: a retriever model and a generation model.
- Retriever model – Responsible for retrieving information from external knowledge sources in response to a query. Once it receives a query, it uses either traditional retrieval techniques, such as SQL queries, or more advanced approaches, such as dense or sparse retrievers, to retrieve the most relevant and accurate information.
- Generation model – Converts the retrieved data into readable content. Once it accepts embeddings from the retriever, it combines the retrieved data with the context of the original query. The data then undergoes natural language processing with the language model to become generated text.
Together, these two components make up a complete RAG flow which looks like this:

- A user makes a query that passes through the RAG model.
- The RAG model encodes the query and compares the text embeddings with external datasets.
- The retriever finds the most relevant information using the chosen retrieval technique, then converts the results into vector embeddings.
- The retriever sends the embeddings to the generator.
- The generator accepts the embeddings and integrates them with the original query.
- The generator passes the results to the language model to produce a final output in the natural language of the user.
This hybrid approach allows RAG to produce more accurate and contextually appropriate responses for LLMs.
Applications of RAG
RAG has applications in a wide range of industries and use cases:
Question-answering systems
One of the primary applications of RAG is the development of robust question-answering systems. RAG is used to retrieve information from diverse sources and generate comprehensive and accurate answers to user queries. RAG systems can outperform traditional methods in providing users with in-depth knowledge in any domain.
Conversational agents
RAG can also be used to enhance the ability of dialog systems or conversational agents, such as chatbots and AI assistants, to provide contextually aware and informative responses. RAG enables chatbots to engage in more meaningful and dynamic conversations with users where they can understand user queries in a broader context and respond with greater accuracy.
Another application of RAG that is beneficial for conversational agents is enriching personalized recommendations. Through a RAG model, chatbots can retrieve information about user preferences, historical interactions, and current trends in various domains such as entertainment, e-commerce, or news so they can offer tailored suggestions. This ensures that recommendations are not just relevant but also appealing to individual users.
Content creation and summarization
RAG has proven to be a valuable tool in creating content and summarizing documents. By selecting information from various sources and using a generative model to paraphrase and synthesize the retrieved content, RAG systems can create high-quality summaries, articles, or other forms of content that are not only coherent but also contain up-to-date information.
Code generation and programming
The field of software development can also benefit from RAG models. They can be used to tap into vast repositories of existing code snippets and documentation, such as GitHub, to assist developers in writing code, debugging, and finding solutions to problems, thereby accelerating, optimizing, and reducing errors in the software development process.
Healthcare support
In the healthcare sector, RAG can be used by AI models to access medical databases, research papers, and clinical knowledge to assist healthcare professionals in diagnosing illnesses, suggesting treatment options, and staying up-to-date with the latest medical literature. RAG helps with streamlining a multitude of tasks as well as the decision-making processes involved in healthcare.
Legal assistance
Access to relevant and reliable information is crucial in the legal industry. RAG models can help legal professionals obtain pertinent case law, statutes, and legal precedents and aid them in time-consuming tasks like legal research and document drafting.
Dynamic compliance management with RAG
In the realm of regulatory compliance, language models struggle to keep up with dynamic regulatory changes, resulting in compliance management systems that rely on LLMs to fall short. RAG can enable LLMs to adapt to the frequent updates and varying complexities and formats of regulatory data and provide an effective solution to real-time compliance management.
RAG can extract relevant and up-to-date information and transform it into adaptive responses, which can help with identifying compliance gaps, accelerating decision-making processes, and maintaining compliance. Here are the advantages of utilizing RAG models for compliance management:
Real-time compliance monitoring
With RAG, organizations can facilitate real-time monitoring of their compliance status to stay updated with any changes in regulations. By continuously analyzing incoming data and comparing it against existing regulations and policies, RAG models can provide organizations with up-to-date insights into their compliance posture. This enables organizations to promptly identify any deviations from regulatory requirements and ensure their compliance at all times.
Proactive risk management
By providing the latest information on their compliance status, RAG empowers organizations to take proactive measures and mitigate risks associated with non-compliance. RAG models can flag potential issues or areas of non-compliance as they arise so organizations can swiftly address these issues and adjust their operational processes accordingly.
Overall, RAG models allow organizations to stay agile and responsive in the face of ever-changing regulatory landscapes. By incorporating real-time compliance monitoring into their workflows, organizations can effectively manage compliance risks and uphold their commitment to regulatory compliance.

How can organizations safely implement RAG?
Through 6clicks’ Responsible AI and Regulatory Compliance solutions, organizations can ensure that their use of RAG models and the processes involved with these systems comply with regulatory requirements.
Organizations can utilize 6clicks’ AI Risk Library, AI Control Set and Policy, and AI System Impact Assessment Template to implement RAG and effectively manage potential AI-related risks while adhering to responsible AI practices.
Organizations can also integrate AI frameworks and standards such as the NIST AI RMF and ISO 42001 into their existing compliance and risk management systems to govern their RAG models. Using the Audit and Assessment capability, organizations can perform assessments against these documents to identify areas of non-compliance.
Enhance AI interactions with Retrieval-Augmented Generation
By facilitating the retrieval and generation of high-quality, reliable, and up-to-date content, RAG streamlines processes, contributes to operational efficiency, and makes way for more sophisticated and contextually aware interactions. Learn how you can implement robust Regulatory Compliance and Risk Management for your RAG model or AI system with 6clicks.

Written by Andrew Lawrence
Andrew is responsible for the company's engineering practices and technical strategy, having led technology teams for over fifteen years. He has a passion for growing engineering teams, empowering them to scale up, and believes in market-leading quality and innovation that creates outstanding product suites. He has successfully led software engineering programs resulting in notable acquisitions. Andrew holds a Bachelor's in Computer Science from the University of Melbourne and is certified in ITIL, project management and solution architecture for the cloud.



